by Jolly Nanda | Aug 5, 2020 | Analytics, Covid, Industry Trends
Prescriptive Analytics
Authored by Ayesha Rajan, Research Analyst at Altheia Predictive Health
Introduction
Here at Altheia Predictive Health, we are constantly improving techniques for disease prediction and diagnosis to improve the lives of people around the world. Where we leave off, companies like IBM pick up and begin applying analytics to the next step in the disease management process which is a treatment plan. Prescriptive analytics in healthcare can refer to several different things but in this article, we will look at prescriptive analytics as it related to the study of prescribed steps for those with chronic conditions to better understand how to manage disease conditions at various stages of a given condition. This can be an extremely useful tool for doctors who are looking at a borderline case and deciding whether or not to begin medication treatments by giving them the ability to see compiled and analyzed data for similar cases.
Discussion
After being diagnosed with a disease, the next question patients and providers have is what steps can be taken to prevent progression of the disease and manage the negative effects of a disease; for some people this is achieved through diet and exercise, for others it may be a prescribed medication and it is highly dependent on several patient factors. Prescriptive analytics is rooted in how to best solve a problem – if the problem is diabetes, a prescriptive model would look at variables in a patient’s file to determine if the problem can be mitigated through diet and exercise. If not, the model would then provide a game plan for how to begin prescribing medicines in the most effective way for any given patient. In diabetes patients, insulin therapy is a common form of treatment where adjustments to a specific individual can be tricky but prescriptive analytics can use the data of similar patients to provide a tried and true treatment plan. Prescriptive analytics can also be used in radiation therapy by weighing various favors, such as treatment location and surrounding organs, to provide a highly targeted treatment plan that treats an area with a calibrated dosage while leaving the rest of the body as unharmed as possible. This is something that we as humans can make educated guesses on but the use of prescriptive analytics is likely much more accurate which means better care for patients.
This field of study also has an incredibly relevant application amidst the Covid-19 Pandemic. Throughout the pandemic data has been collected on patients such as their age, BMI, gender, ethnicity, presence of chronic conditions and more. All of this information combined with their response to treatment plans provides a unique opportunity to apply analytics – by looking at these sets of data together, we can use artificial intelligence to understand which patients respond better to certain treatment plans. This provides a great opportunity to improve Covid-19 survival rates and lower the number of patients suffering from long-term complications as a result of Covid-19.
Conclusion
Prescriptive analytics in healthcare is essentially a way for analytics to troubleshoot disease conditions by providing a data-based treatment plan. By providing physicians with analytical tools, such as prescriptive analytics, we can significantly improve their success rate in treatment plans and as a result improve the quality of life for hundreds of thousands of people.
by Jolly Nanda | Jul 30, 2020 | Uncategorized
Blockchain Technology in Data Management
Authored by Ayesha Rajan, Research Analyst at Altheia Predictive Health
Introduction
Big data in healthcare is a hot topic right now – we constantly hear about how analytics can predict health conditions, the health of a population, the spread of disease, support the efforts of wearable devices and more. There are a lot of cutting-edge developments in this field, however, they will all be undermined if data management in healthcare does not also catch up with these new tools and technologies. In this article we will explore the role blockchain technologies play in healthcare.
Blockchain
One use of blockchain and crypto-technology in healthcare is to increase security and safety of data. Patient records are highly sensitive information that have been exposed to data breaches in the past and that is unacceptable but was hard to prevent in the era before blockchain technologies. Now, highly randomized and privatized algorithms can be used to increase the security surrounding these files and ensure a patient’s safety and right to privacy. This effort has been highly prioritized by nearly every healthcare organization including the United States government. A company working in this area, called Factom, has received $200,000 in grants from the Department of Homeland Security to further research and development in this area (Daley).
Another area in which blockchain can make great strides in healthcare is in communication networks. Currently, miscommunication costs the healthcare industry about $11 billion USD per year mainly due to the current process of coordinating medical records – that is a significant amount of money that could be much better spent elsewhere (Daley). Utilizing blockchain technology to create a means of transferring information privately and accurately should absolutely be a priority when using blockchain technology.
Blockchain can also help protect information in the healthcare supply chain by providing secure and reliable processes to guarantee the authenticity of medicine. This can be done by creating a distribution system that marks a point of origin and keeps track of a shipments location and who it came in contact with. This ensures the medicines delivered to patients are from a legitimate supplier and have not been tampered with. In relation to recent developments in the field of medicine, this can also be useful in tracking the safety of medications and patients if their medication happened to come in contact with an employee who contracted Covid-19 – the tracking ledger can ensure that anyone who came into contact with contaminated products after the infected employee is notified and recommended to be tested.
Conclusion
Blockchain technology is popping up in nearly every industry as a means to accurately and privately transfer information. This type of technology is extremely useful in the healthcare space and has many applications in disease control and prevention. However, another area in healthcare it can impact significantly is in data collection and management. By securing the data of patient’s, healthcare organizations not only ensure the peace of mind of patients but also better diagnoses by ensuring the accuracy of the data communicated. Blockchain technologies can also prevent delays in diagnosis caused by slow-moving communication which continues to support the notion that blockchain in data management is a powerful tool that can greatly benefit patients.
Works Cited
Daley, Sam. “15 Examples of How Blockchain Is Reviving Healthcare.” Built In, 2020, builtin.com/blockchain/blockchain-healthcare-applications-companies.
by Jolly Nanda | Jul 23, 2020 | Uncategorized
Discussing Recent Changes in the Availability to Covid-19 Data
Authored by Ayesha Rajan, Research Analyst at Altheia Predictive Health
Introduction
Just as we were beginning our weekends last week, our news channels were dominated by headlines detailing the story of how the Trump Administration has stripped the CDC of its access to Covid-19 data. Throughout the Covid-19 Pandemic the CDC has been an integral part of getting key information out to the public through press conferences, visual education material, data reports and more. For those reasons, this development is incredibly surprising and begs the question of who the public should look to for trusted information regarding the spread of and how to protect themselves from Covid-19. This also brings up several issues for hospitals and resource allocation, as well as many other issues for organizations relying on accurate data to make decisions.
Discussion
The first question that you might ask in this regard is – how does the CDC get its Covid-19 data? The CDC was getting its data by hospitals directly sending them information. This move by the Trump Administration tells hospitals to bypass the CDC in data reporting and report information regarding all Covid-19 cases, as well as that hospitals available number of beds and ventilators, to the Department of Health and Human Services. This is incredibly problematic because many of the available models and projections made for Covid-19 have come from private and university researchers who rely on the fact that the CDC makes its data public, but the Department of Health and Human Services does not operate the same way. In fact, this has already impacted many researchers who claim that their models and prediction algorithms began underperforming when access to data was quietly taken away. This begs the question of whether or not who this data will be made available to and if this is simply a method to politicize the information the public is being given regarding Covid-19. Many scientists, physicians and leaders in the field have “long expressed concerns that the Trump administration is politicizing science and undermining its health experts [and feel that] the data collection shift reinforced those fears.”
Michael Caputo, a spokesperson for the Department of Health and Human Services, has said that his department and the CDC would share data so that it remained available to the public, however, many states, including Kansas and Missouri, have not received timely access to relevant data, with some hospitals saying they’ve experienced up to a week of lag time in receiving requested data. As hospitals across the nations are seeing new peaks in their Covid-19 cases, hospital workers have also said that this change in reporting of data is highly disruptive to their usual processes and taking time away from more pressing matters. Some workers also express a sense of frustration knowing that this increase in workload will only lead to less access to data in the future. Additionally, the Trump Administration has repeatedly made claims that the way testing is reported in the United States is leading to confusing reports and information regarding Covid-19. This brings up serious concerns for many physicians who worry that this thought process will lead to false or inaccurate reporting of Covid-19 cases in an attempt to support the goals of the current Administration.
Conclusion
The recent changes in the reporting of Covid-19 cases and relevant information has been widely criticized by leading officials, physicians and the general public as an unnecessary stunt by the Trump Administration. Most have concurred that the decision puts many people at risk by complicating a process that has been in place throughout the pandemic and has supported the public access to and research of Covid-19 data. As we move forward in the battle against Covid-19, we must analyze how we can better access reliable data and provide hospitals with the tools necessary to prepare and succeed in their endeavors.
Works Cited
[1] Stolberg, Sheryl Gay. “Trump Administration Strips C.D.C. of Control of Coronavirus Data.” The New York Times, The New York Times, 14 July 2020, www.nytimes.com/2020/07/14/us/politics/trump-cdc-coronavirus.html.
by Jolly Nanda | Jul 16, 2020 | Analytics, Covid, News
Revisiting Our Covid-19 Predictions in Florida: What We Got Right, What We
Missed and What’s Next
Authored by Ayesha Rajan, Research Analyst at Altheia Predictive Health
Introduction
In our last article we reflected on our predictions regarding the spread of Covid-19. We made observations and predictions in March using linear regression and found that our data had an error rate of less than 10% when looking at the American population as a whole. However, many states had different rules and regulations for social distancing, mask wearing and other precautions, so we also made predictions based on different levels of regulations to predict the impact Covid-19 on hospitals and ICU beds. In this article, we will explore the accuracy of those predictions for the state of Florida and tools that can help us going forward as many states begin to see their number of Covid-19 cases spiking again.
Analysis and Interpretation
In our analysis we made the following predictions for the state of Florida based on different levels of precautions taken:
Predicted Hospitalizations with All Precautions Taken
April | May | June | Mid-June | July | August |
2,208 | 2,028 | 18, 251 | 19, 264 | 10, 139 | 2,208 |
Predicted Hospitalizations with Some Precautions Taken
April | May | June | July | August |
2,208 | 10,139 | 35,487 | 10,139 | 2,028 |
Predicted Hospitalizations with No Precautions Taken
April | May | Mid-May | June | Mid-June | July | August |
2,208 | 20, 278 | 55, 766 | 40, 557 | 10, 139 | 3,042 | 2,028 |
While looking at this data, keep in mind that the number of hospital beds available in the state of Florida is 55,727. Looking back on our data, it’s clear that our model was very conservative. On one hand, we did accurately predict peaks and the fact that Florida would be overwhelmed with Covid-19 cases, however, we predicted that even with no precautions we would begin to see this come to an end in August. As we come to mid-July, Florida is the latest state to break American records with 15,000 new Covid-19 cases in one day which indicates that the end of the battle against Covid-19 in Florida is nowhere near over (Linton). In fact, as of July 7th, 2020, “at least 56 intensive care units in Florida hospitals reached capacity” with another 35 showing less than 10% availability (Chavez).
The natural question to ask when making models such as these is how to improve them. In some ways, our model was conservative – in a no precautions setting, it was almost impossible that Florida could be in back in the same place it was in April. However, some error can be attributed to the lack of knowledge regarding the spread of coronavirus in March. We created these predictions based on Imperial College London’s pandemic model, however, the pandemic model could not account for the various changes, such as when and how certain things would reopen and was also based on the fact that we had a predicted end date. It was also limited in the fact that it was an agent-based model and not a stochastic model, which accounts for randomness such as the random meeting of two people and the impact they would have on their community if they were infected with Covid-19. The most accurate prediction models take in a lot more information about a more concentrated population. For example, it would not try to make every studied population follow the same multipliers because it would consider much more specified information about that population such as the occupations of a population, their ages and activities, their political engagement and beliefs, their methods of transportation, their attendance of religious functions and even more.
Conclusion
What we can take away from this interpretation of data is that there is not a one size fits all model for pandemic predictions. Different counties, cities, states and countries all follow different schedules and habits and while most hospitals in Florida are overwhelmed, there are also likely some that barely see any or limited Covid-19 related issues. For this reason, it is extremely important to consider a lot more information about a more specified population than to use broad, blanketing equations; especially when the data is used for resource allocation. As we continue to battle Covid-19, it is important to take precautions such as wearing a mask in public places, practicing social distancing and maintaining good hygiene.
Prevention
Take a look at the image below to see low to high-risk situations and understand how you can limit your exposure to Covid-19.

by Jolly Nanda | Jul 9, 2020 | Analytics, Covid
Reflecting on Our Covid-19 Predictions and How Analytics Can Continue to Help
Authored by Ayesha Rajan, Research Analyst at Altheia Predictive Health
Introduction
As we climbed towards Covid-19 peaks across the country in March and April, we at Altheia Predictive Health looked at linear and exponential regression models of predicted case counts. We also used that data to make predictions regarding where hospitals would be overwhelmed. In recent weeks many states are seeing those peaks come back, so it seemed like the right time to look back at and reflect on our past Covid-19 predictions and look at how analytics can help us prepare for the second wave that many states are seeing come their way.
Discussion
When writing our first articles about Covid-19 we made two types of predictions for the U.S.– one used exponential regression and the other used linear regression. As we noted in our previous articles, the curve had begun to flatten by the time we made our exponential regression observations so here we will focus on linear regression. For linear regression of total cases in the United States, our prediction table, as well as the actual case numbers and percent error are as follows:
Date | Predicted Value | Actual Value | Percent Error |
April 10th, 2020 | 469,140 | 512,010 | 8.37% |
April 11th, 2020 | 495,604 | 542,498 | 8.64% |
April 12th, 2020 | 522,068 | 570,358 | 8.46% |
April 13th, 2020 | 548,532 | 597,452 | 8.18% |
April 14th, 2020 | 574,996 | 624,893 | 7.98% |
April 15th, 2020 | 601,460 | 655,569 | 8.25% |
April 16th, 2020 | 627,923 | 685,712 | 8.42% |
Though it is dependent on the scenario, a percent error of less than 10% is generally accepted as a fair prediction which bodes well, not only for validation of our predictions, but also for validation of linear regression as a tool to use in the planning, analysis and allocation of hospital resources.
New Technology
Big data has been used at nearly every step in the battle of Covid-19. The first step is, of course, prevention. The most important part in prevention is to practice social distancing and other preventative measures and to maintain good hygiene and health. However, in terms of analytics, community tracking of Covid-19 cases can use contact networks to help mitigate risk in some ways. Think of someone who tested positive for Covid-19 as a member of a social network, such as Facebook. If you are friends with that person, you are in their network and your friends, even if they are not directly “friends” with the original positive case, are at risk because of their connection to you. Disease tracking works in a similar way by creating a network of everyone who came in contact with a positive case patient and who came in contact with those people, and so on.
The next step is diagnosis and condition management and to help this effort, John McDevitt and his team at New York University have used artificial intelligence and big data to predict which Covid-19 patients are likely to experience severe cases. They did so by identifying biomarkers in blood tests of patients who died and patients who survived their battle with Covid-19. The research team found that there was a difference in the levels of C-reactive proteins, myoglobin, procalcitonin and cardiac troponin I. The patients who died of Covid-19 had elevated levels of these measurements; the researchers factored this into their risk equations (Kent).
The next step in the battle against Covid-19 is the creation of a vaccine. While this is still very much “in the works,” scientists at 15 universities, including Johns Hopkins University, University of Wisconsin, University of Alabama, Pennsylvania State University and others, have partnered to share data samples of electronic health records to aid in the creation of a vaccine. The motivation behind this collaboration is to gather as much data about Covid-19 patients as possible in order to quickly identify patient responses to antiviral and anti-inflammatory treatments (Shephard).
Conclusion
As many states are hit with a second wave of Covid-19 cases, it is reassuring to know that analytics can be an extremely helpful tool in every stage of the disease. Analytics can identify at-risk groups that may need to take extra precautions in protecting themselves due either to exposure or preexisting conditions. Analytics tools are also useful at the care management stage where doctors can identify patients who need ventilators more than others if, as demonstrated during Italy’s first wave, there comes a time when decisions need to be made about where resources should be focused. Finally, these predictive tools will be helpful in the creation of a vaccine, especially when collaboration across research institutions is encouraged and beneficial. Ultimately, the existence and widespread use of analytics in disease prevention and management is an encouraging fact as it greatly accelerates our ability as a society to bounce back from the struggles caused by Covid-19.
Prevention
Take a look at the image below to see low to high-risk situations and understand how you can limit your exposure to Covid-19.
Works Cited
Kent, Jessica. “How Artificial Intelligence, Big Data Can Determine COVID-19 Severity.” HealthITAnalytics, 15 June 2020, healthitanalytics.com/news/how-artificial-intelligence-big-data-can-determine-covid-19-severity.
Shephard, Bob. “Enlisting Big Data to Accelerate the COVID-19 Fight – News.” UAB News, 2020, www.uab.edu/news/research/item/11371-enlisting-big-data-to-accelerate-the-covid-19-fight.
by Jolly Nanda | Jul 2, 2020 | Analytics
Quantifying Chronic Obstructive Pulmonary Disease
Authored by Ayesha Rajan, Research Analyst at Altheia Predictive Health
Introduction
Chronic Obstructive Pulmonary Disease, or COPD, is a chronic disease characterized by the inflammation of the lungs. This inflammation causes air to be obstructed from the lungs and can result in difficulty breathing, coughs, mucus and wheezing (Mayo Clinic). It affects at least 16 million Americans and 250 million people globally – it is a leading cause of death nationally and globally (Healthline). There are three main causes of COPD – the primary cause is exposure to tobacco smoke, the secondary is exposure to air pollution or fumes and the tertiary cause is due to asthma. Most COPD cases are the result of the first two causes and, as a result, are somewhat preventable; however, there is more to the story. COPD can also be the result of genetics and is correlated with the presence of other diseases which the field of analytics can help take into account in trying to predict COPD risk. As analytics continues to impact nearly every aspect of our lives, it is hopeful that it can also be a tool to help those suffering from Chronic Obstructive Pulmonary Disease.
Key Data Points
The main pieces of data needed to evaluate risk of COPD are lung function tests, the results of a chest x-ray, arterial blood gas analysis, sputum (mucus) test and the results of an Alpha-1-antitrypsin blood test. The Alpha-1-antitrypsin test is a genetic test that tells a patient whether or not they are deficient in the protein that protects the lungs from irritants; those who are deficient are likely develop COPD at a young age. This piece of information can be key to prevention because once COPD is present, it is irreversible (Healthline). Additionally, because COPD can cause hypertension, heart disease, diabetes and other health problems, it can be useful to look at the general metabolic panel.
New Technology and Relevant Studies
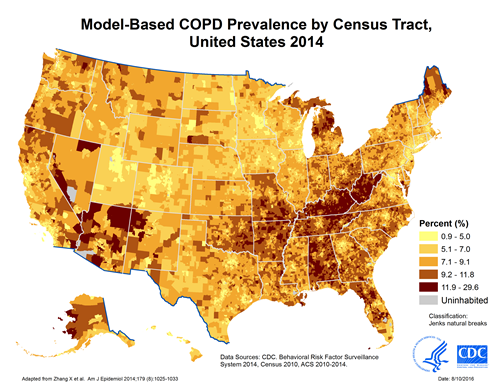
Another way to look at COPD from a data standpoint is through geocoding which looks at health conditions as the result of a surrounding environment. Geocoding is not a new form of data visualization but can be immensely helpful. For example, take a look at the image below:
This image shows us where prevalence of COPD is highest. Researchers can use this information to find commonalities between these cities to identify causes of COPD that may have been overlooked or not even considered. For example, one study found that in their studied population, lower winter ambient temperatures could be associated with increased COPD hospital admissions (Serra-Picamal). This is not surprising, because asthma symptoms worsen with colder air so one could expect to see similar statistics for COPD, however, it is not an assumption one can make without data-based proof. Of course, this is just one study, but it goes to show that data can pick up trends that we as humans cannott validate without proof.
Aside from diagnosis and progression predictions, analytics can also be used to improve care for COPD patients. At Intermountain Healthcare, a scoring system called Laboratory-based Intermountain Validated Exacerbation (LIVE) predicts mortality, morbidity and hospitalization rates for patients with COPD. The score is calculated by using hemoglobin, albumin, creatinine, chloride and potassium values to determine which patients are at risk of progression or death and to identify which patients need to move onto advanced care. In the first test of the LIVE scoring system, researchers found that it was able to successfully identify which patients were low or high risk at time of hospital admission and could produce a score that matched to the appropriate plan of care (Kent).
Prevention
The best thing someone can do to prevent COPD is to stop smoking or stop exposure to secondhand smoke and air pollution. Following that, the best way to prevent COPD is to live a healthy lifestyle by maintaining good hygiene, keeping up to date with flu and pneumonia vaccines, eating a healthy diet and staying active.
Conclusion
Chronic Obstructive Pulmonary Disease is a disease that is highly preventable by maintaining a healthy lifestyle, however, there are factors that make certain groups more at risk than others. By combining the power of data with medicine, we can continue to compile a list of those factors to help those who are at risk prevent the disease before they have it. Analytics can also help in disease and care monitoring to improve hospital care for patients. As this field continues to develop, we can hope to see lower rates of incidence of COPD in the future and continually improving care for those who do have it.
Works Cited
“CDC – Data and Statistics – Chronic Obstructive Pulmonary Disease (COPD).” Centers for Disease Control and Prevention, Centers for Disease Control and Prevention, 5 June 2018, www.cdc.gov/copd/data.html.
“COPD.” Mayo Clinic, Mayo Foundation for Medical Education and Research, 15 Apr. 2020, www.mayoclinic.org/diseases-conditions/copd/symptoms-causes/syc-20353679.
Kent, Jessica. “Predictive Analytics, Risk Scores Improve Care for COPD Patients.” HealthITAnalytics, 9 Aug. 2019, healthitanalytics.com/news/predictive-analytics-risk-scores-improve-care-for-copd-patients.
Roland, James. “COPD Diagnosis: Spirometry, X-Ray, and 6 More Tests for COPD.” Healthline, Healthline Media, 17 Nov. 2018, www.healthline.com/health/copd/tests-diagnosis#takeaway.
Serra-Picamal, Xavier, et al. “Hospitalizations Due to Exacerbations of COPD: A Big Data Perspective.” Respiratory Medicine, W.B. Saunders, 16 Jan. 2018, www.sciencedirect.com/science/article/abs/pii/S095461111830009X.
Thomas, Jen. “COPD: Facts, Statistics, and You.” Healthline, Healthline Media, 14 May 2019, www.healthline.com/health/copd/facts-statistics-infographic#8.
by Jolly Nanda | Jun 25, 2020 | Analytics
Improving Predictive Healthcare Models by Filtering for Racial Differences in Data
Authored by Ayesha Rajan, Research Analyst at Altheia Predictive Health
Introduction
Risk calculators are at the forefront of analytics in healthcare – using ranges to understand who might be at risk of contracting a disease and when they might contract it, is a powerful tool but it doesn’t stop there. Analytics can also help us to better understand disease progression and manage symptoms, however, these tools often underserve racial and ethnic minorities because of the lack of inclusion of race-adjusted ranges in the metabolic and blood panels. To better serve the general population, racial differences in health data must be taken into consideration and used where applicable to make analytics a beneficial tool to all. In recent years, several studies have explored this topic and we will take a look at some of them in this article.
Current Problem
The biggest challenge in this research space is collecting data – for example, the link between breast cancer and race in women proves that at least some disparities in cancer diagnoses boil down to racial differences. One of the contributing factors to this disparity is many randomized clinical trials become stalled due to lack of enrollment (Zewde)[1].
Consequently, data segmented by racial differences can be difficult to obtain. The next biggest challenge is identifying when race is the impactful variable. Many people of the same race and ethnicity often share similar cultural practices so relationship, lifestyle, location, and other variables can influence the interaction of panel data and race. One-way that the National Center for Biotechnology
Information (NCBI) suggests tackling this is by administering more comprehensive questionnaires so that such parameters can be factored out to identify the root cause of a disparity.
Emerging Technology and Studies
This field of research is central to our mission at Altheia Predictive Health. Our proprietary predictive health models take race into account when creating risk ranges to ensure that each individual receives information that is personalized to their background. We can see in much of our research that risk ranges vary among race and ethnic groups with many minorities being classified at a higher risk than Caucasian Americans even with the same variable being measured. By including race as a parameter in predictive algorithms, we can train machines to better interpret and apply the most accurate data possible and, as a result, increase the accuracy of these algorithms.
There is more to this area of research; outside of diagnosing and managing diseases, analytics also identifies racial disparities in care management programs. In a study at Portland State University, researchers observed patients in a hospital emergency room and studied the way nurses and physicians interacted with people of varying races and ethnicities. Researchers found that “Black patients were 32 percent less likely to receive pain medication than white patients, while Hispanic patients were 21 percent less likely to receive pain medication than their white counterparts. Asian patients were 24 percent less likely to receive pain medication than white individuals. This was despite the fact that black and Hispanic patients reported higher average pain scores than white patients.” [2]
Conclusion
Ultimately, analytics applications are a tool and just a piece of the puzzle; there is still an element of human touch that will always be necessary to bring together the entire picture. Without taking race and ethnicity into account, analytics applications lack accuracy and context that human interpretation can add to predictive analytics models so that they can better serve a much wider community. As this field continues to develop, the biggest struggle for researchers will continue to be lack of enrollment in studies. However, by expanding the questions asked and information documented on Electronic Health Record for those who do participate in studies, we can make great strides in determining when race and ethnicity are strongly correlated to disease contraction and progression.
by Jolly Nanda | Jun 20, 2020 | Analytics
Do Analytics Discriminate? Disparities in Algorithms Across Various Racial and Ethnic Groups
Authored by Ayesha Rajan, Research Analyst at Altheia Predictive Health
Introduction
Patients who come in with concerns about kidney function are always tested for their glomerular filtration rate(GFR). It is interesting to note, the GFR is factored into the Kidney Failure Risk Equation and other algorithms differently for African Americans but remains standard across all other ethnic and racial minority groups. However, across several other predictive health algorithms and risk calculators, racial differences in the metabolic panel are typically not considered. Given that different racial and ethnic groups have different predispositions to and progressions of diseases, this is an area that needs improvement. As the field of medicine moves towards analytics to predict patient risk, medication needs and other factors, it is important to consider the benefits of increased accuracy by taking race into consideration when creating algorithms, as well as the implications of biased algorithms.
Current Problem
In 2019, NBC reported on an algorithm written by Optum that was heavily biased. The algorithm was used to rank patients that would most benefit from a care program that aimed to manage responsible use of medication and to keep patients out of the hospital. In a group of 6,000 black patients and 44,000 white patients, only 17.5% of people recommended for the program were black despite the fact that the black patients had 26.3% more chronic conditions. Developers had to ask themselves why this was the case and found that their cost-based algorithm left behind black patients because of monetary biases – black patients spend $1,800 less per year than white patients with the same conditions. This means that black patients with the same or worse chronic conditions than white patients were left behind because of their inability to pay. Once Optum balanced that aspect of the algorithm, they saw the number of black patients recommended for the program jump from 17.5% to 46.5% (Gawronski). This example shows disparities in algorithms that we can not always anticipate but that still negatively affect certain racial groups.
Analytics As A Solution
In October of 2019, George Washington University received a grant to study these types of disparities. The four-year study is still in its earliest stages, but it will help researchers better identify the relationships between race and disease prediction. Yan Ma, who is the Vice Chair of the Department of Bioinformatics at George Washington University, says that one of the biggest and easiest steps that can be taken to improve this situation is for large databases to include a patient’s ethnic group and/or race in their information. In fact, it’s surprising that many data bases do not already have this data. If they did, it would make machine learning and artificial intelligence even more powerful tools than they are currently (Kent).
The Centers for Medicare & Medicaid Services echo the same sentiment in their studies of using racial data to improve healthcare treatment for all patients, citing lack of clear and reliable data as the biggest roadblock to their research and the area most in need of improvement. Currently, Medicare uses (and has been using for quite some time) a method called geocoding to target at risk communities. Geocoding makes predictions about a person’s health based on the characteristics of the areas in which they live. It works in the way that many would like algorithms to account for racial differences; it takes into consideration the population health and trends of a community to make more targeted predictions about a person’s health. This method is limited because it is not exact and is highly dependent on areas that self-segregate. It does however lay out the groundwork for how a study could separate certain groups to identify their specific risk factors and general health.
Conclusion
While data science tools such as machine learning and artificial intelligence have significantly advanced the field of medicine, there are many people that are left behind because of biased equations. In order to best serve all communities it is important that healthcare providers and companies that are creating predictive algorithms take differences in racial predispositions into account and adjust metabolic and blood panels in the same way to provide the best care to each unique patient.
Works Cited
Gawronski, Quinn. “Racial Bias Found in Widely Used Health Care Algorithm.” NBCNews.com, NBCUniversal News Group, 7 Nov. 2019, www.nbcnews.com/news/nbcblk/racial-bias-found-widely-used-health-care-algorithm-n1076436.
Kent, Jessica. “Machine Learning to Uncover Racial Disparities in Healthcare.” HealthITAnalytics, 31 Oct. 2019, healthitanalytics.com/news/machine-learning-to-uncover-racial-disparities-in-healthcare.
Llanos, Karen. “Using Data on Race and Ethnicity to Improve Health Care Quality for Medicaid Beneficiaries.” CHCS, 2006, www.chcs.org/media/Using_Date_to_Reduce_Health_Disparities.pdf.
by Jolly Nanda | Jun 10, 2020 | Analytics
Authored by Ayesha Rajan, Research Analyst at Altheia Predictive Health
Introduction
Chronic Kidney Disease is a condition involving the gradual loss of kidney function; your kidneys filter blood to remove waste and toxins which in turn helps control blood pressure and maintain red blood cell function and bone health so their ability to function properly is clearly very important. Chronic Kidney disease is caused by presence of diabetes, high blood pressure, obstruction of the urinary tract and range of other conditions including glomerulonephritis, interstitial nephritis, polycystic kidney disease, vesicoureteral and pyelonephritis (Mayo Clinic). Many patients do not realize they have Chronic Kidney Disease until it has progressed quite far in the 5 stages but when symptoms do show up, they include itching, muscle cramps, lack of appetite, nausea, unusual swelling, changes in frequency of urination and trouble breathing or sleeping. Once diagnosed, the disease is managed by slowing the progression of kidney damage to prevent end-stage kidney failure which necessitates dialysis or a kidney transplant. Currently, 15% of the American population (37 million people) has Chronic Kidney Disease but many of them do not know it – this is a frightening data point given that 340 people begin dialysis treatment every that and that kidney disease is the 9th leading cause of death in the United States (CDC). Additionally, UC San Francisco has calculated that CKD costs $79 billion dollars for Medicare patients and predicts that 16.7% of the population will contract CKD by 2030 which shows a clear need for further research in this area (Kent).
Key Data Points
Several factors increase a patients’ risk of chronic kidney disease including presence of diabetes or hypertension, heart disease, smoking activity, obesity, race (African Americans, Native Americans and Asian Americans are all higher risk race groups), family history and age (Mayo Clinic). These factors are often factored into predictive algorithms along with blood panels which hold key variables such as Albumin to Creatinine Ration (ACR), Serum Creatinine, Blood Urea Nitrogen (BUN) and Glomerular Filtration Rate (GFR). Urine tests can also measure relevant variables such as Urine Protein, Microalbuminuria and Creatine Clearance Rate. All of these variables measure kidney function and can predict the onset or stage of Chronic Kidney Disease.
Current Research
An important study out of Cairo University utilized multiple algorithms to study the importance of physical variables in class identification of CKD. The study used probabilistic neural networks, multilayer perceptron, support vector machine and radial basis function algorithms to identify which algorithm would most accurately identify a patients’ stage of CKD. The study found that the probabilistic neural network algorithm yielded the highest classification accuracy at 96.7% and used that information to add weight to each considered variable and improve the prediction performance of CKD stage diagnosis. This study showed that each variable was, indeed, not weighted equally. In fact, there was a significant difference between the 100% importance of serum creatinine and a 9.256% importance of hypertension in diagnosis. This is important in identifying at risk groups because, clearly, not everyone with hypertension will have CKD but those at high risk serum creatinine levels are very likely to need treatment (Rady). Research conducted in the United States around CKD draws from the following databases for information: The National Health and Nutrition Examination Survey; United States Renal Data System; Kaiser Permanente; and Veterans Affairs Healthcare System. These databases are essential to the use of artificial intelligence and machine learning techniques because they can provide ranges for many of the physical variables listed above. However, outside of physical variables, research has also been done on nonconventional risk factors of CKD. For example, several studies have evaluated air pollution using “of land-use regression and spatiotemporal models that utilized satellite remote-sensing aerosol optical depth data” to associate air pollution with incidence of CKD in a population. These studies have concluded that increased air pollution could be correlated with incidence of CKD and decrease of glomerular filtration rate. Another study using artificial intelligence used clinical notes to evaluate predictors of CKD and found high-dose ascorbic acid and fast food consumption to be novel predictors (NCBI). Artificial intelligence can actually do most of the heavy lifting in studies like these in which we can gain insight into the impact of factors that we may have never otherwise considered to be relevant in the study of Chronic Kidney Disease.
Conclusion
Chronic Kidney Disease affects (and will continue to affect) a significant number of the population and it is clear that more research needs to be done in this area. To make that possible, some things need to change. For example, accessibility to medical data needs to be made easier so that research can happen at various levels, i.e. medical, academic and corporate. This ensures that those who want to research these topics can do so without the time constraints of existing rules and regulations so that developments can be made mainstream to patients and providers in the timeliest matter. Additionally, federal funding could be redirected to research in this area to improve data processing techniques which are currently fragmented and hinder the success rate of the existing multidimensional algorithms.
Prevention
The necessary steps for preventing Chronic Kidney Disease are very much in line with leading a generally healthy life. Mayo Clinic recommends that one maintain a healthy weight through physical exercise and calorie reduction, not smoke and follow responsible usage guidelines for over-the-counter medications as abusing pain relievers can cause kidney damage. Furthermore, if you are at risk, it is important to check in with your physician frequently to track and manage symptoms of Chronic Kidney Disease (Mayo Clinic). If you are unsure about whether or not you might be at risk of contracting kidney disease, you may consider using the CDC’s Chronic Kidney Disease Risk Calculator at: https://nccd.cdc.gov/CKD/Calculators.aspx#tab-Bang.
Works Cited
“Chronic Kidney Disease Basics.” Centers for Disease Control and Prevention, Centers for Disease Control and Prevention, 7 Feb. 2020, www.cdc.gov/kidneydisease/basics.html.
“Chronic Kidney Disease.” Mayo Clinic, Mayo Foundation for Medical Education and Research, 15 Aug. 2019, www.mayoclinic.org/diseases-conditions/chronic-kidney-disease/symptoms-causes/syc-20354521.
Kent, Jessica. “Chronic Kidney Disease Patients Face Significant Care Disparities.” HealthITAnalytics, HealthITAnalytics, 17 July 2019, healthitanalytics.com/news/chronic-kidney-disease-patients-face-significant-care-disparities.
Rady, El-Houssainy A., and Ayman S. Anwar. “Prediction of Kidney Disease Stages Using Data Mining Algorithms.” Informatics in Medicine Unlocked, Elsevier, 7 Apr. 2019, www.sciencedirect.com/science/article/pii/S2352914818302387.
Zeng, Xiao-Xi, et al. “Big Data Research in Chronic Kidney Disease.” Chinese Medical Journal, Medknow Publications & Media Pvt Ltd, 20 Nov. 2018, www.ncbi.nlm.nih.gov/pmc/articles/PMC6247601/.